Chapitre 5 Sentiment Analysis
Une des volontés de cet article était de pouvoir extraire le sentiment exprimé pour chaque commentaire et par chaque lover d’adada. Pour réaliser cela, nous allons travailler avec l’API NLP de Google16 et le package googleLanguageR17. Je ne vais pas m’attarder sur les fonctions et le package. Le but étant de voir dans quelle mesure les valeurs reportées par l’API font sens.
5.1 Partial function
Tout d’abord, nous allons créer une fonction avec des arguments spécifiques avec la fonction partial. Nous utiliserons cette fonction sur chaque commentaire pour récupérer le score entre (-1 et 1) et la magnitude (0, Inf).
Cette fonction sera mappée sur notre colonnes comments.
gl_auth("token.json") #<- Google API Key
sent <- adada_tbl3 %>%
select(rowid, lovers, comments) %>%
mutate(lovers = tolower(lovers)) %>%
distinct_all() %>%
filter(!is.na(comments)) %>%
ungroup() %>%
mutate(nlp = map(comments, get_sent)) %>% # <- execute the fonction
mutate(res = map(nlp, "documentSentiment"))Il ne reste plus qu’à joindre la table des sentiments avec notre table de travail. Nous pouvons passer à l’exploration de ces nouvelles données.
adada_tbl4 <- adada_tbl3 %>%
mutate(lovers = tolower(lovers)) %>%
left_join(sent, by = c("rowid", "lovers", "comments")) %>%
unnest(res, keep_empty = TRUE) 5.1.1 Quel est le score moyen des commentaires ?
adada_tbl4 %>%
distinct(lovers, comments, title, .keep_all = TRUE) %>%
summarise(magnitude = mean(magnitude, na.rm = TRUE), score = round(mean(score, na.rm = TRUE), 2)) %>%
kable("html", escape = FALSE, align = "l", caption = "Score Moyen") %>%
kable_styling(bootstrap_options = c("striped", "condensed", "bordered"), full_width = T)| magnitude | score |
|---|---|
| 0.9543094 | 0.15 |
Nous avons un score de 0.15. De prime abord nous pouvons dire que l’ensemble des commentaires est assez neutre. Cela dit, nous pouvons avoir aussi des extrêmes qui s’annulent et donc avoir des commentaires assez tranchés. La moyenne des magnitudes équivaut à 0.9. Plus cette valeur est élevée plus nous pouvons avoir une variation de sentiments de phrases en phrases. En effet le score et la magnitude retournés sont valables pour l’ensemble des phrases composant le commentaire. Chaque phrase pouvant avoir un score différent. Voyons ce que cela donne sur un graphe avec des boxplots.
5.2 Quelle distribution des scores et des magnitudes ? (1)
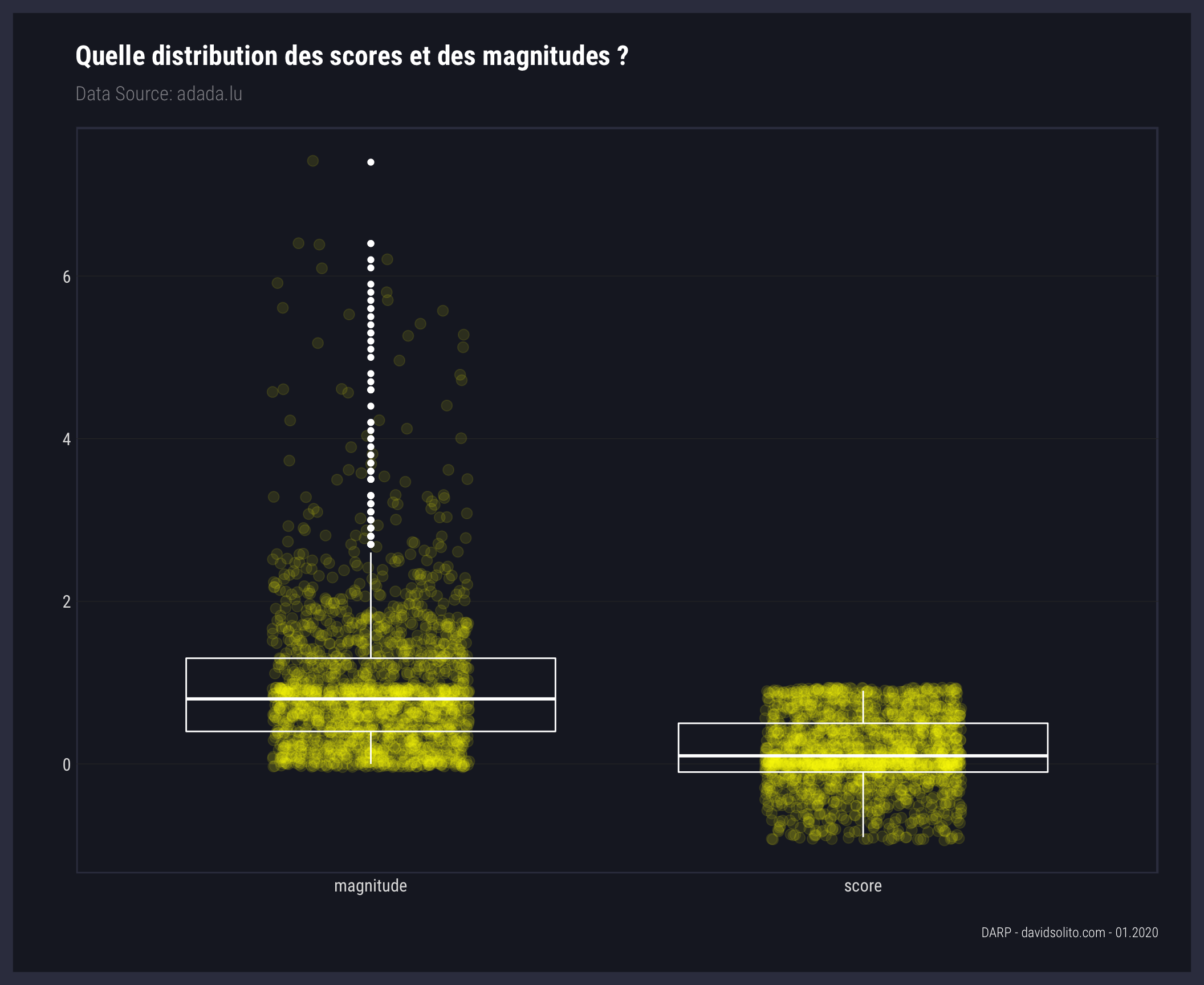
Quelques commentaires ont une magnitude de plus de 4. Un density plot va nous permettre de mieux voir la dispersion des scores.
5.3 Quelle distribution des scores et des magnitudes ? (2)
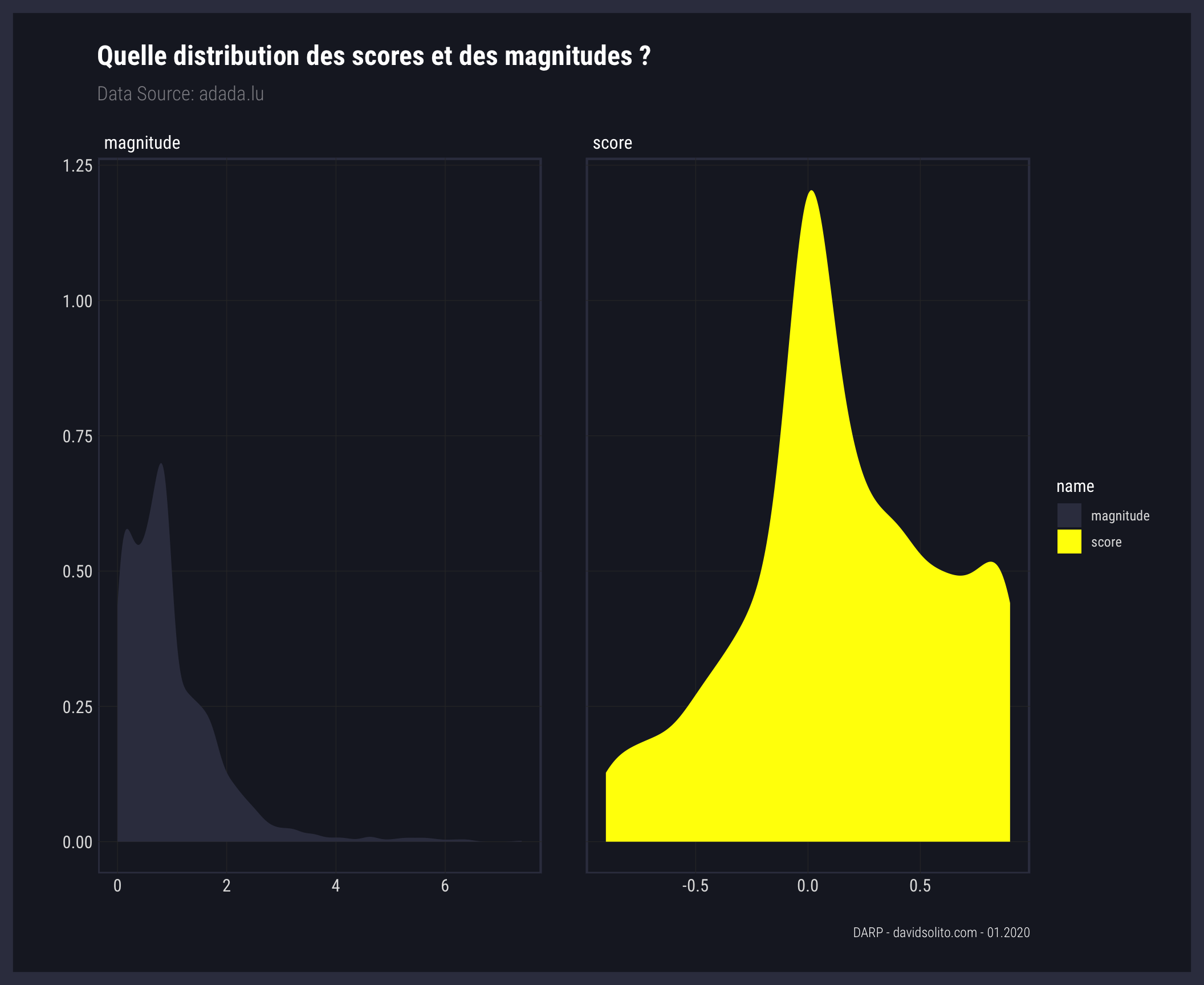
Nous observons sur le graphe de droite que nous avons plus de commentaires supérieurs à 0.5 qu’inférieurs à 0.5.
5.4 Quel volume de commentaires par type de sentiment et par lover ?
Voyons à présent la répartition en ajoutant un facteur de sentiment : negative - neutral - positive pour chaque lovers.
adada_tbl4 %>%
distinct(lovers, comments, title, .keep_all = TRUE) %>%
filter(!is.na(lovers)) %>%
mutate(range = case_when(score >= - 0.25 & score <= 0.25 ~ "neutral",
score > 0.25 ~ "positive",
score < - 0.25 ~ "negative")) %>%
count(lovers, range) %>%
arrange(desc(n)) %>%
filter(n > 2) %>%
# filter(lovers %in% top10_lovers) %>%
filter(!is.na(range)) %>%
filter(range != "neutral") %>%
mutate(n = if_else(range == "negative", -n, n)) %>%
kable("html", escape = FALSE, align = "l", caption = "Volume type sentiment") %>%
kable_styling(bootstrap_options = c("striped", "condensed", "bordered"), full_width = T)| lovers | range | n |
|---|---|---|
| bizness | positive | 88 |
| bizness | negative | -36 |
| adada | positive | 32 |
| troismille | positive | 31 |
| madinina | positive | 28 |
| gianmarco | positive | 19 |
| georgette | positive | 17 |
| j+r | positive | 14 |
| charles | positive | 13 |
| troismille | negative | -12 |
| madinina | negative | -11 |
| coincoin | negative | -10 |
| raoul | negative | -10 |
| raoul | positive | 10 |
| adada | negative | -9 |
| le p’tit poucet | positive | 9 |
| nimportequoici | negative | -9 |
| mathias | positive | 8 |
| misspitch | positive | 8 |
| vogelpik | positive | 8 |
| coincoin | positive | 7 |
| fbk | positive | 7 |
| jpé | positive | 7 |
| le petit poucet | negative | -7 |
| anne | positive | 6 |
| georges | positive | 6 |
| georgette | negative | -6 |
| julien | positive | 6 |
| lenny baer | negative | -6 |
| bio | negative | -5 |
| le petit poucet | positive | 5 |
| mark zuitneberg | positive | 5 |
| misspitch | negative | -5 |
| nimportequoici | positive | 5 |
| bill murray | negative | -4 |
| fbk | negative | -4 |
| frank kaiser | positive | 4 |
| j+r | negative | -4 |
| karine | positive | 4 |
| le p’tit poucet | negative | -4 |
| polux | positive | 4 |
| popol | positive | 4 |
| priscillia | positive | 4 |
| vogelpik | negative | -4 |
| alex | positive | 3 |
| anne | negative | -3 |
|
|
negative | -3 |
| baccri | positive | 3 |
| bertrand | positive | 3 |
| bill murray | positive | 3 |
| didier | positive | 3 |
| didier chandelon | positive | 3 |
| donnovan | negative | -3 |
| filipe | positive | 3 |
| fred | positive | 3 |
| james bond | negative | -3 |
| jean | positive | 3 |
| jude19 | positive | 3 |
| justjack | positive | 3 |
| kratz | negative | -3 |
| la ménagère de 95ans | positive | 3 |
| madgirl | positive | 3 |
| marc | positive | 3 |
| mathias | negative | -3 |
| mike | positive | 3 |
| p_a | positive | 3 |
| sacha heck | positive | 3 |
| smile | positive | 3 |
| vincent j | positive | 3 |
| yann | positive | 3 |
| z | positive | 3 |
Mettons cela sur un graphique en ne gardant que les lovers avec plus de 2 commentaires à leur actif.
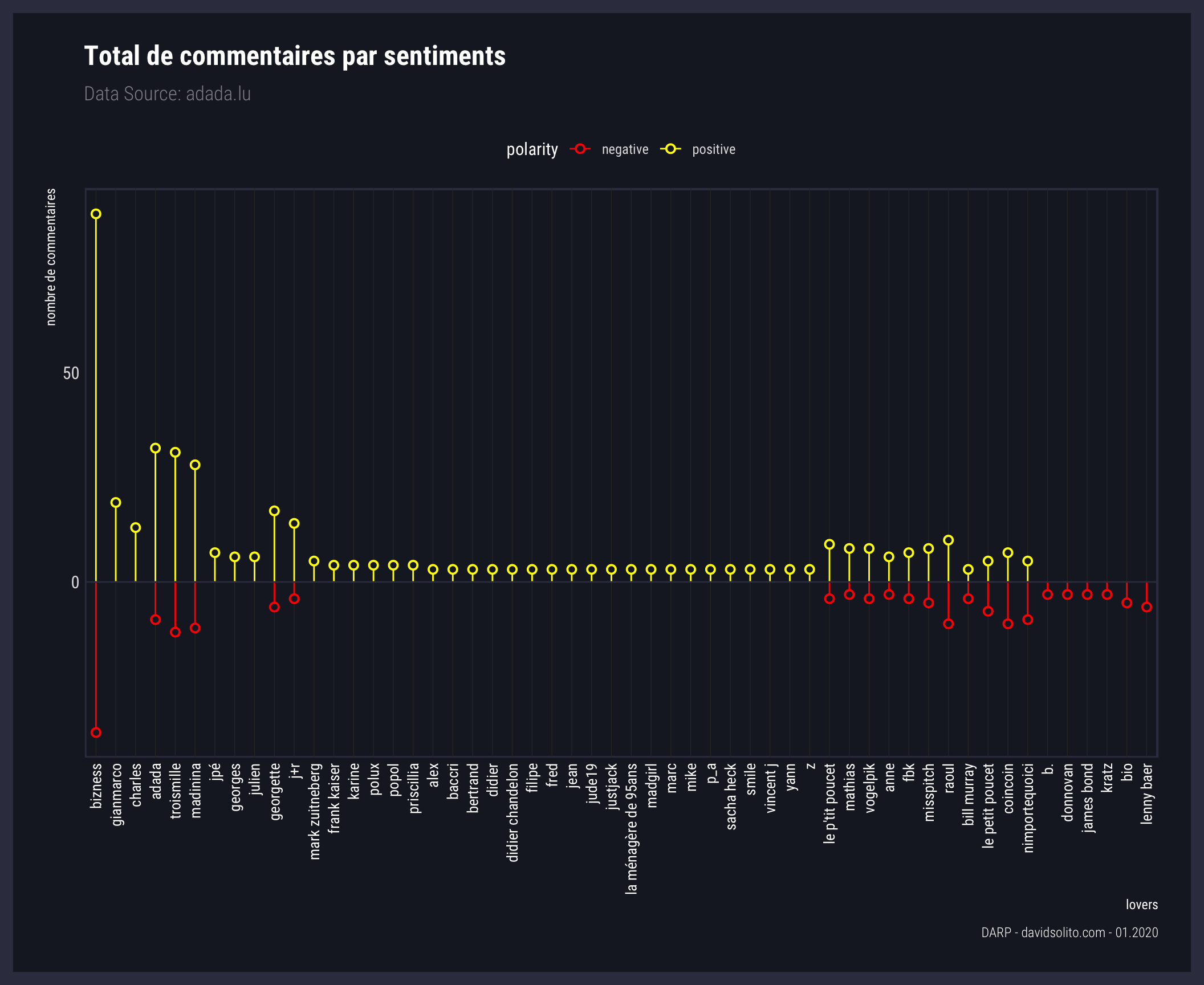
En prenant les extrêmes donc positif et négatif (sans les sentiments neutres), nous pouvons mieux visualiser la polarité de chaque lovers. Pour avoir une vue globale sur cette polarité, nous allons afficher l’ensemble des lovers sur ce graphique. Étant donné le nombre de lovers que cela représente, nous supprimerons leur labélisation.
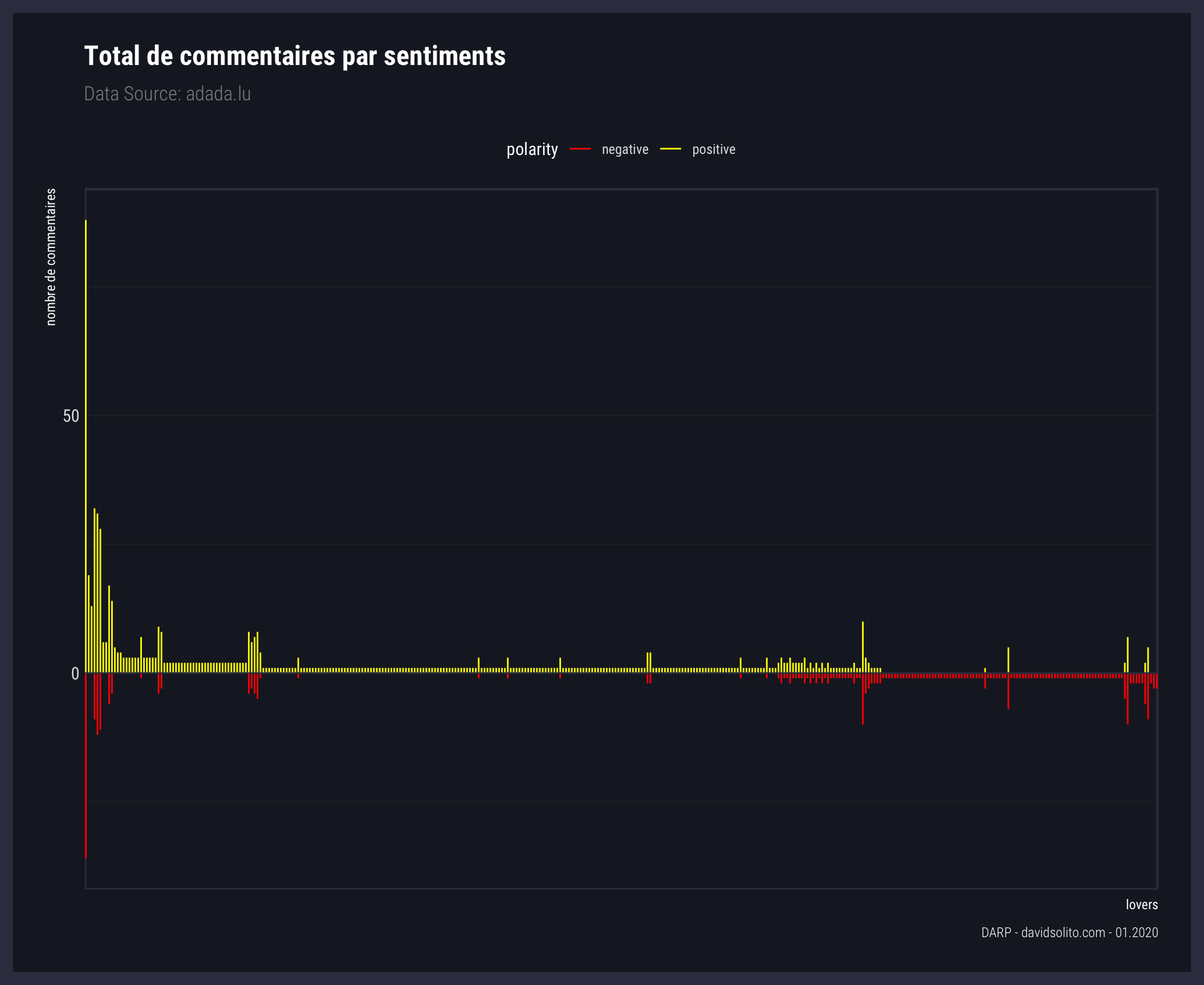
Nous avons ici la photographie de la polarité des commentaires d’adada.
5.5 Quel volume de commentaires par type de sentiment et par agence ?
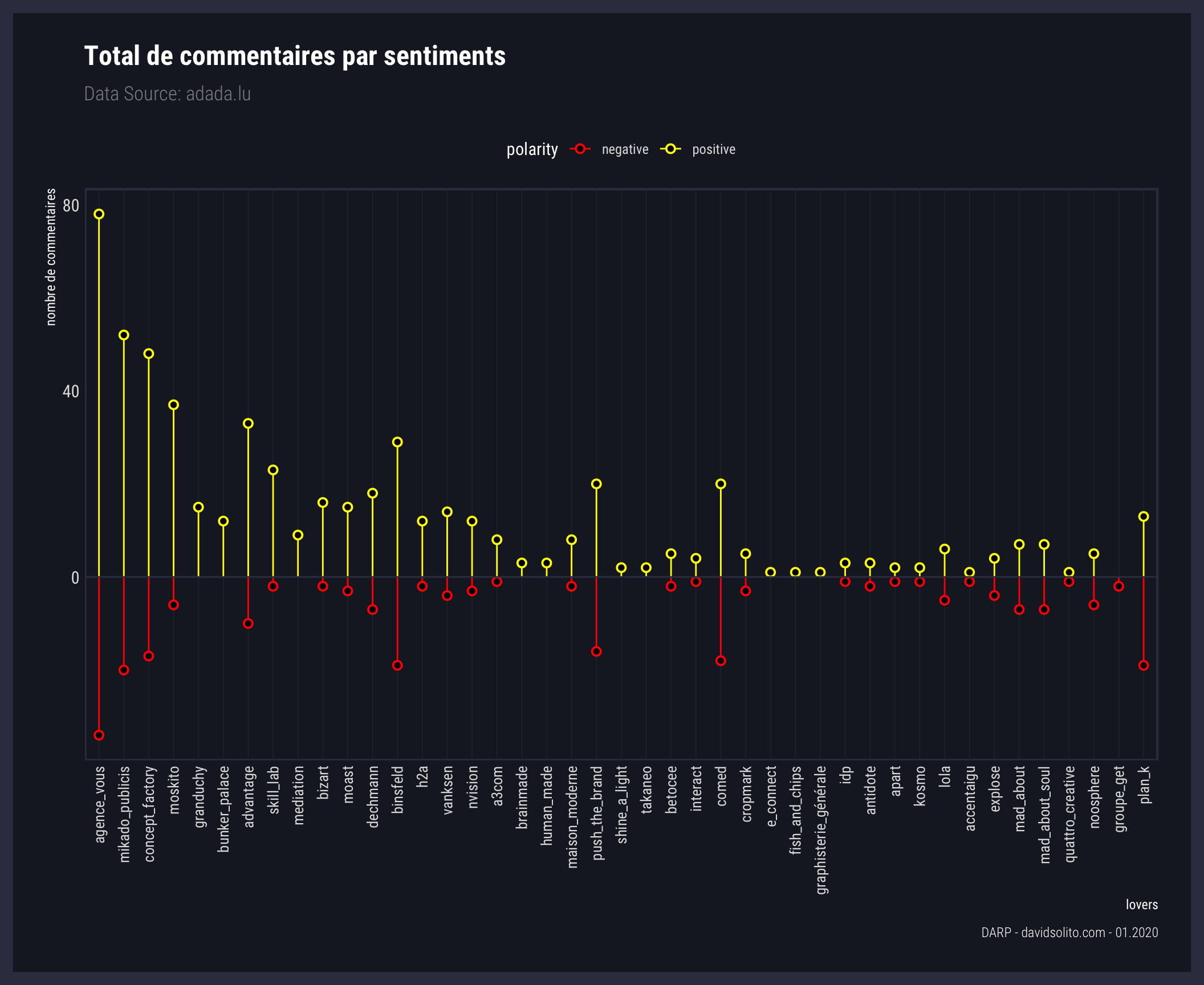
L'agence VOUS compte le plus de commentaires positifs et négatifs. Peu d’agences représentées sur ce graphe comptabilisent que des commentaires positifs (moskito, granduchy). Il est néanmoins nécessaire de prendre en considération que les commentaires peuvent être négatifs sans forcément être attribué à l’agence. Un commentaire peut être évalué comme négatif à juste titre tout en étant une réponse à un commentaire négatif lui précédant. C’est-à-dire que nous aurions 2 commentaires négatifs pour l’article, mais dont le second est une réponse au premier commentaire. Ce graphique illustre donc la polarité des commentaires par agence, mais n’est pas l’évaluation de l’agence. Cette notion est importante à considérer afin d’éviter de mauvaises interprétations du résultat.
5.6 Quelle différence de sentiments ?
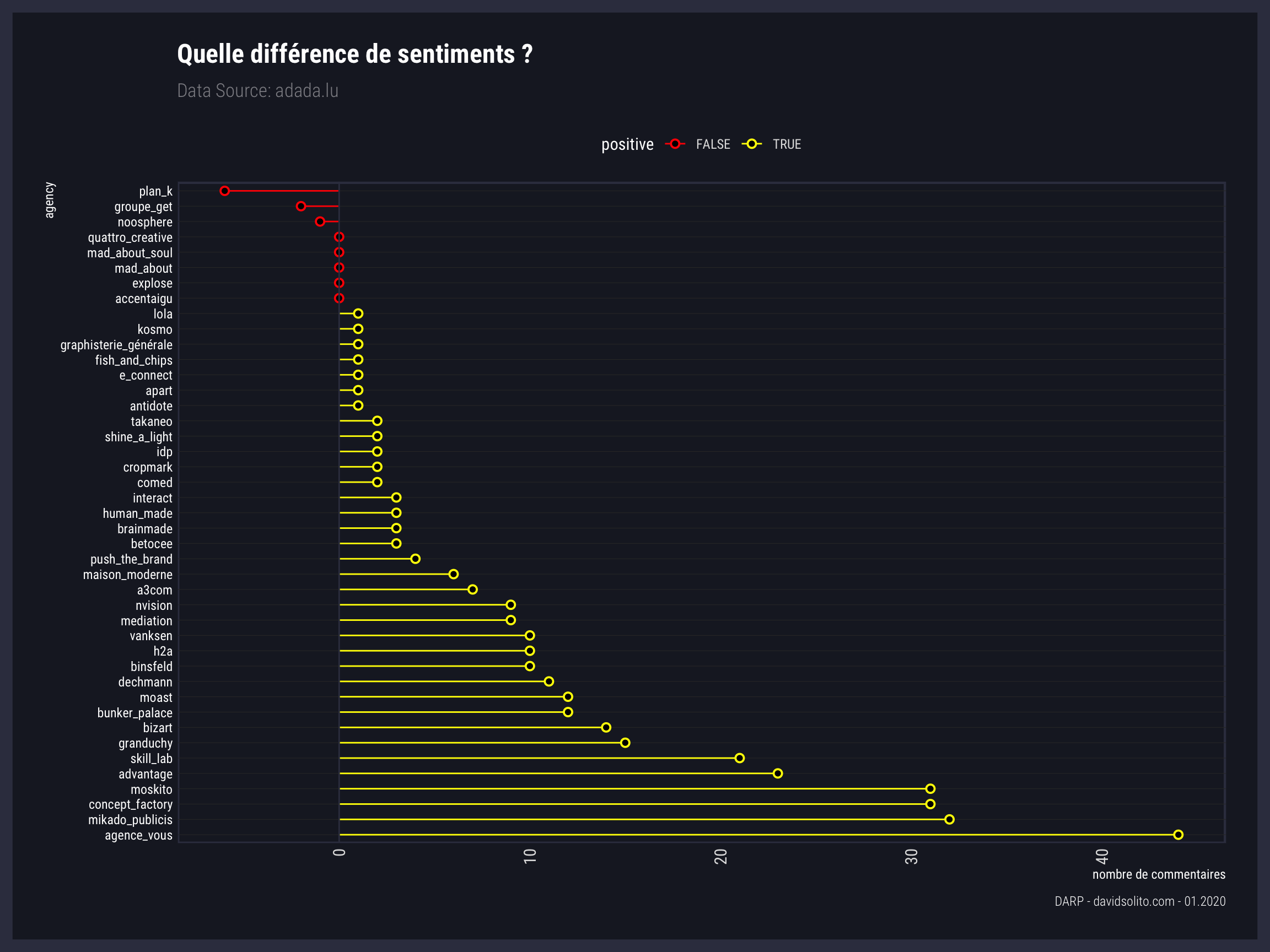
Nous soustrayons les commentaires négatifs des positifs pour ne garder que la différence. Ceci nous permet de visualiser si le nombre de sentiments négatifs dépasse les sentiments positifs et vice-versa. Quelques agences comptabilisent plus de commentaires négatifs que positifs.
5.7 Matrice de positionnement des lovers
Pour ce dernier graphe, nous allons positionner chaque lovers selon leur magnitude moyenne et score moyen. La magnitude retournée par Google représente les variations que nous pouvons avoir dans l’analyse d’un texte comprenant plusieurs phrases. Un peu comme un tremblement de terre. (Chaque commentaire est constitué de plusieurs phrases chacune évaluée par le modèle NLP de Google avec un score spécifique). Le score nous donne la polarité du texte comme vu précédemment.
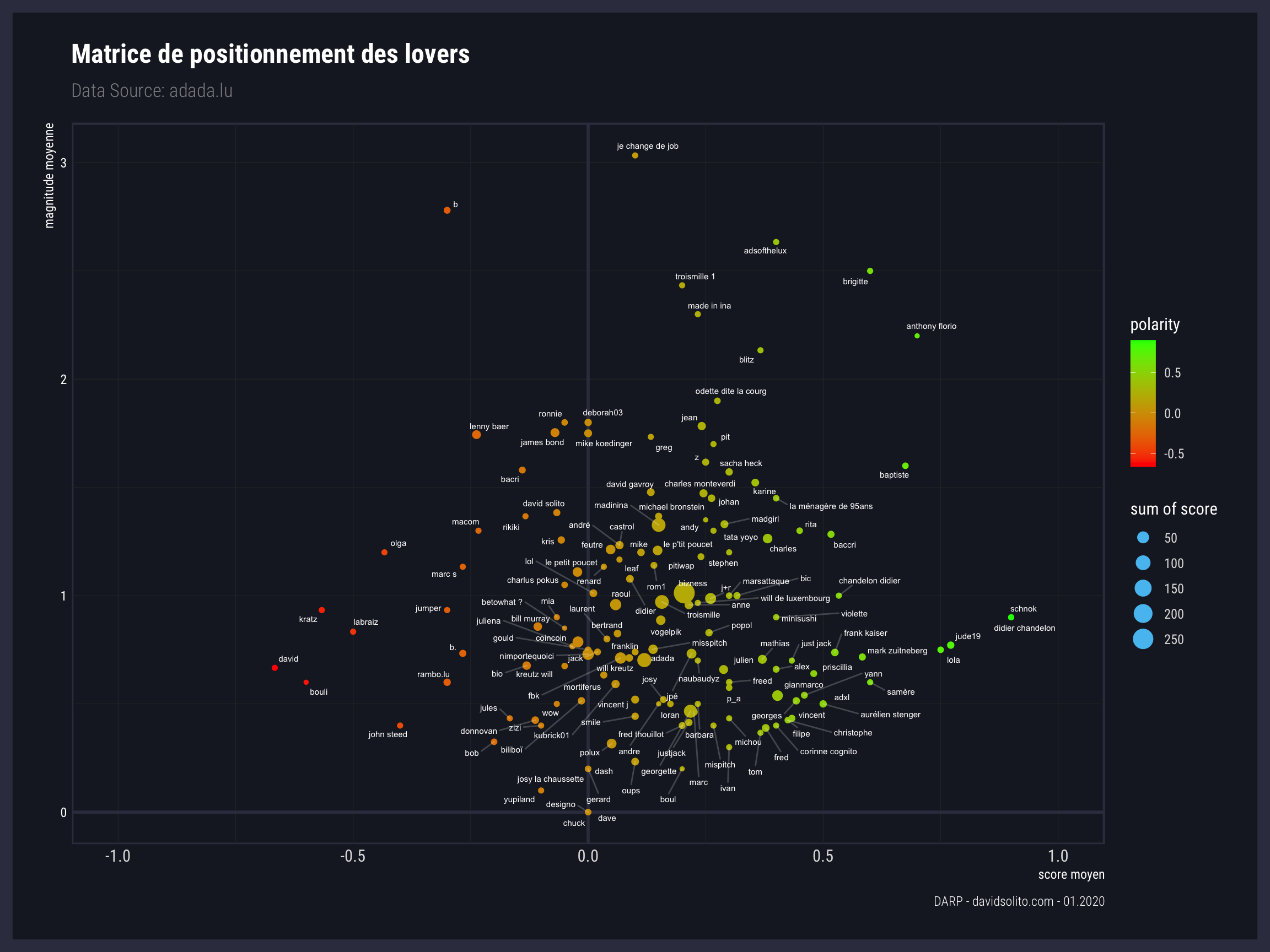
Nous voyons ici le positionnement d’un ensemble de lovers sur ce graphique. Peu ont un score moyen négatif. Certains ont une taille plus importante. Celle-ci est déterminée par la somme de ces scores. Cela donne une certaine intuition aussi sur le volume de commentaire laissé par la personne. Je vous laisse trouver les différents lovers que vous avez pu rencontrér tout au long de cette lecture et de vos lectures sur adada.
5.8 Ce n’est que le début…
Nous voici arrivés au terme de cette analyse. Nous avons vu au travers des différents chapitres comment nous pouvions analyser le contenu d’un site. Il est possible d’aller encore plus loin en ajoutant à cette analyse l’analyse le trafic, le comportement et l’interaction des visiteurs. Il serait possible aussi d’analyser le contenu de chaque article plutôt que les titres. Cela permettrait par ex. de modéliser un modèle de classification de contenu (topics) qui attribuerait une probabilité de correspondance à un topic (sujet) avec une méthode populaire : Latent Dirichlet allocation (LDA), mais cela sera pour une autre fois sans doute.
J’ai pris beaucoup de plaisir à écrire ce document malgré le travail que cela a pu représenter. J’espère que cela vous a plu. Si vous avez des questions, n’hésitez pas à me laisser un message sur twitter.